在公司工作3年有余,主导经历的项目大大小小也有十几个,挑一些有代表性的项目来做一些总结。
酒店收益–预测分析平台
先上一个数据的流程图:
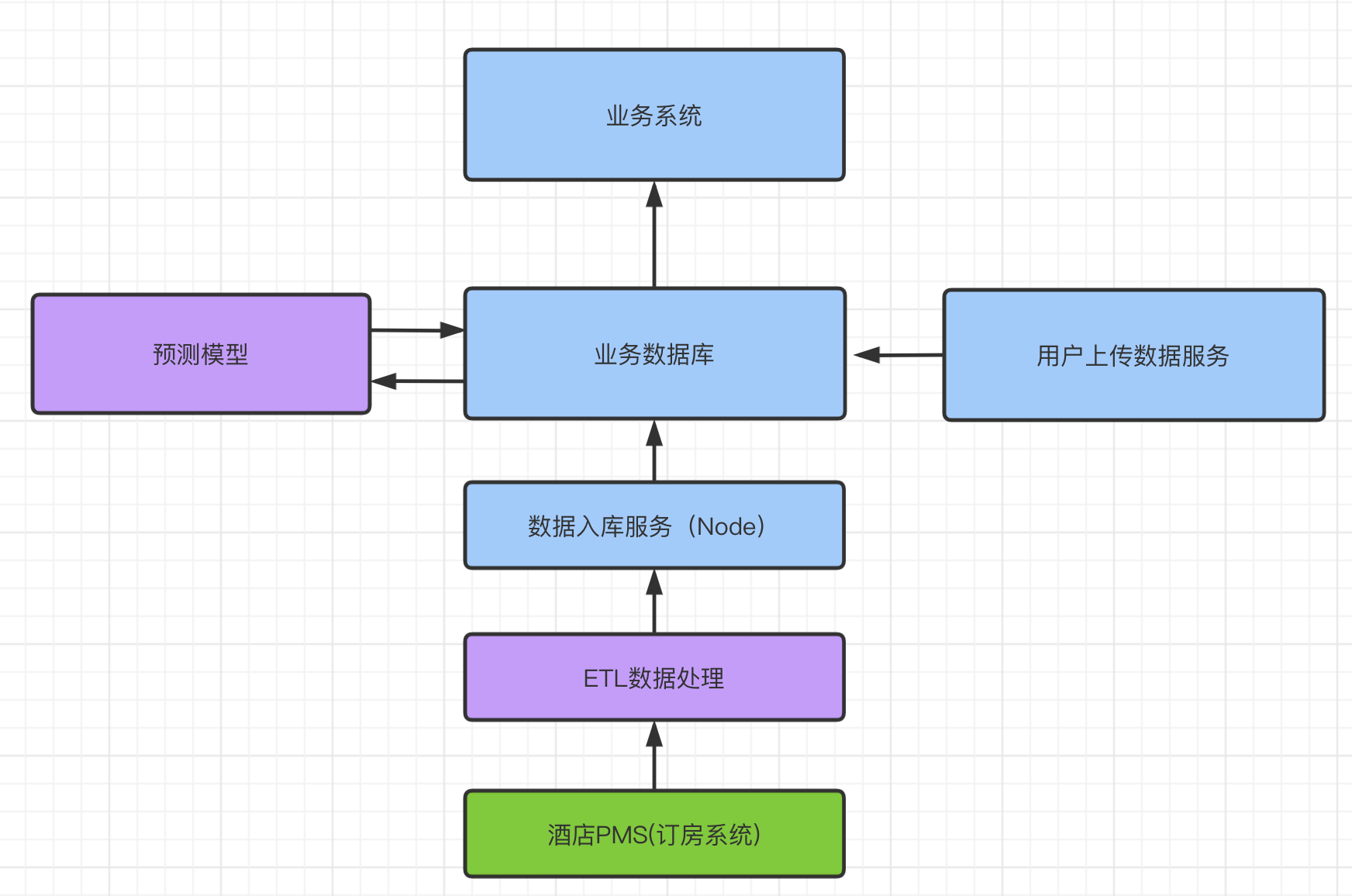
数据来源
系统数据来源有两个:
- 酒店订房系统(PMS)直连数据
- 酒店用户上传数据
因为与我们合作的PMS服务商数量有限,一部分使用我们系统的酒店用户采用的是其他厂商的PMS,只能通过上传数据来使用预测分析平台。
PMS直连数据
PMS数据到达我们公司内部大数据平台,经过ETL数据清理,得到我们需要的部分数据。
我们作为业务方,提供给ETL服务接口,来进行数据入库。单天的数据量在1GB左右,初始化多酒店历史数据量在10GB左右。对于Node来说,显然这么大量的数据不可能单批次入库,所以采用队列的形式,将数据拆分成小数据包,依次进行入库操作。队列使用Kue,上手相对简单。
用户上传数据
这个其实是作为业务系统的一个功能,我们将上传数据的相关内容拆分为一个子服务。该服务进行excel的接收、解析、落成JSON文件,通过数据库,建立一个简单的队列服务,前端通过轮询的方式进行入库状态查询。
预测模型
模型组通过数据库来与系统进行数据关联,当模型监控到数据变化时,触发模型进行数据预测,给系统提供预测数据。
业务系统
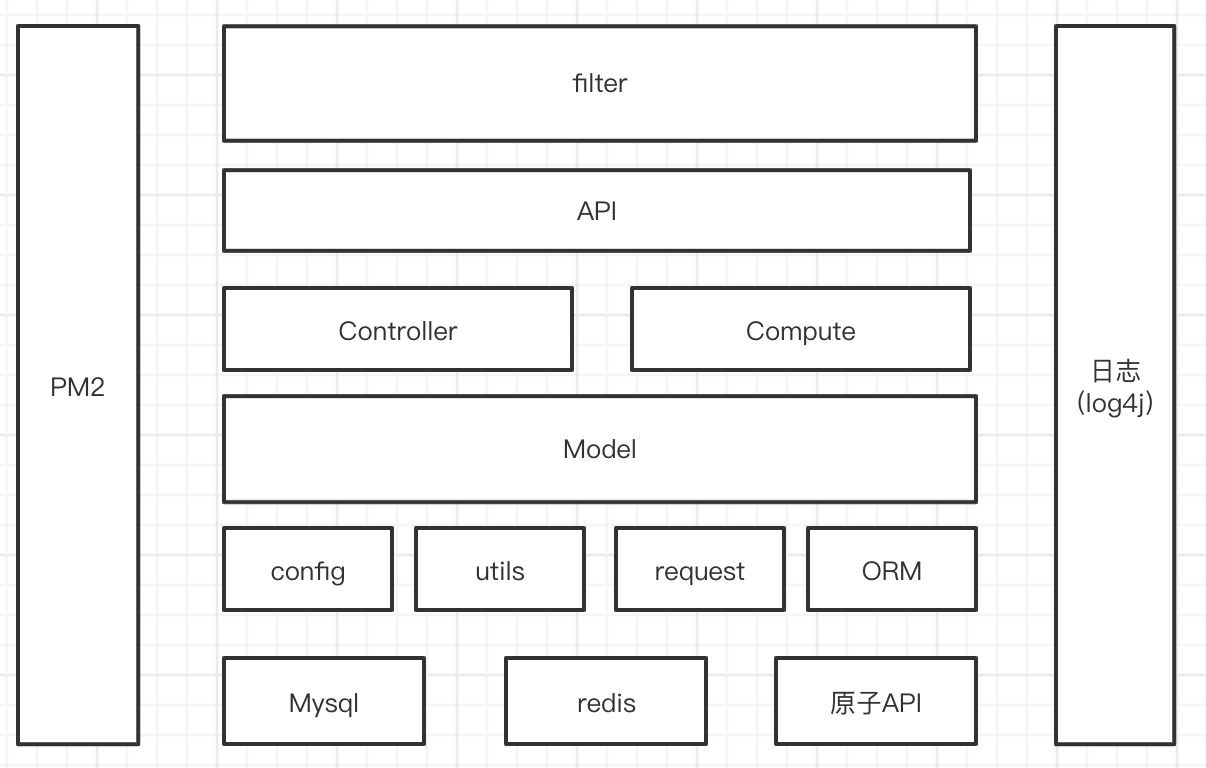
服务端
框架采用的是Express,在这个基础上结合当前的业务现状出来的一整套框架,给一张图:
日志
应用日志是通过log4j来收集的,按照天写成文件,存储在到本地磁盘。一个http请求进入到服务后,会有一个唯一的key会贯穿整个http请求的生命周期,如下图:
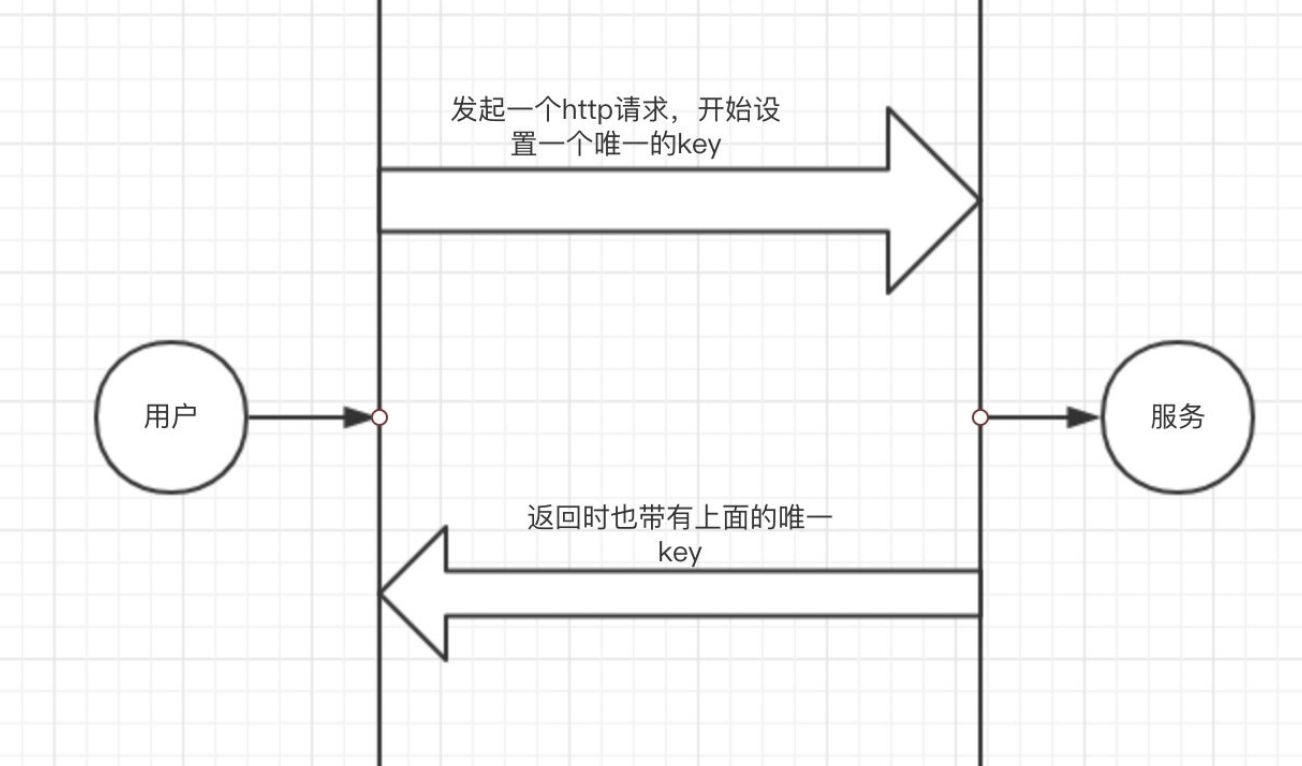
最终在写入每一条日志时,都是会带有该标记。目的是如果当前系统有一个异常操作,可以快速锁定整个流程。
config
config包含3个配置项 环境相关、应用启动、nginx配置。
应用启动配置项会选择当前的环境变量,根据不同的环境变量启动不同的环境变量配置。
nginx配置就是一个单纯的nginx配置文件,不同环境唯一的差异就是静态资源缓存和ssl的配置。
环境配置包含端口(创建项目时自动生成)、第三方服务的配置、数据库相关配置、一些应用相关的配置。
分层
首先看一下业务模型
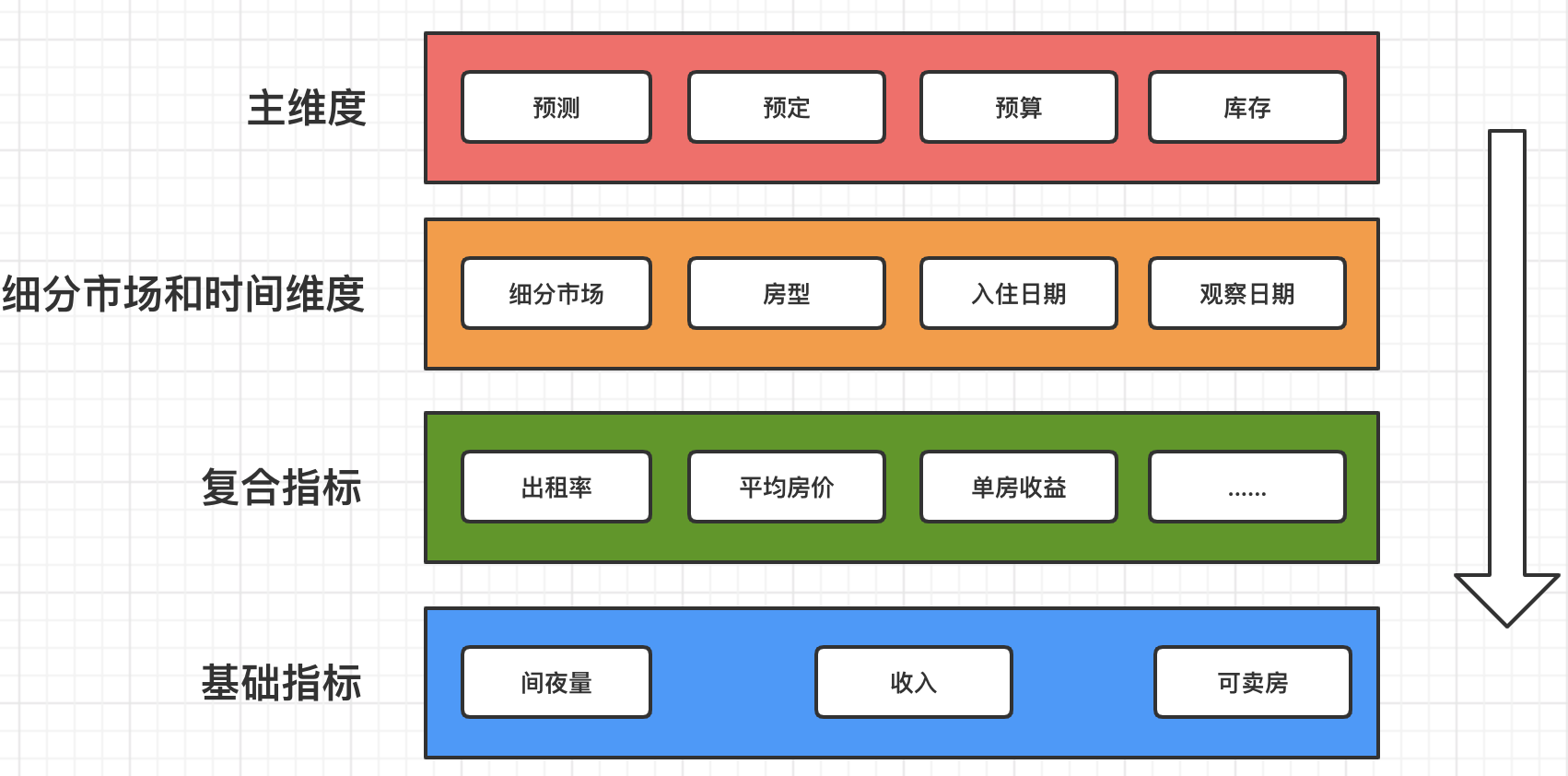
controller层负责维度相关的处理,compute层来进行复合指标的计算。
由于众所周知的原因,js在处理精度计算时会出现问题,所以使用decimal.js来计算各指标。
这样整个服务设计其实非常容易达成了。而且指标计算的服务可以抽象成一些通用的服务,所有的项目都基于这些服务来完成。
ORM
ORM是一个自研发的东西,主要支持的是mysql、redis。功能包含通过sql的方式增删改查、事物、分库分表支持、批量插入/更新优化、sql安全的处理等功能。
路由
路由通过文件夹自动生产,更好维护和管理。
数据库
数据膨胀较快,如果不采取措施会造成读取及写入变慢。
分库分表业内其实有很多成熟的中间件可以用,但是目前为止团队的精力和对中间件的理解贸然上一个中间件带来的问题可能也不在少数,所以设计了2张路由表来做简单的映射,通过映射关系,应用服务来做服务的动态切换。
服务端相关体会:服务端和客户端最大的差别在于一个是稳定另一个是体验,所以服务端还是要在运维层面做工作,来保证服务的稳定性。
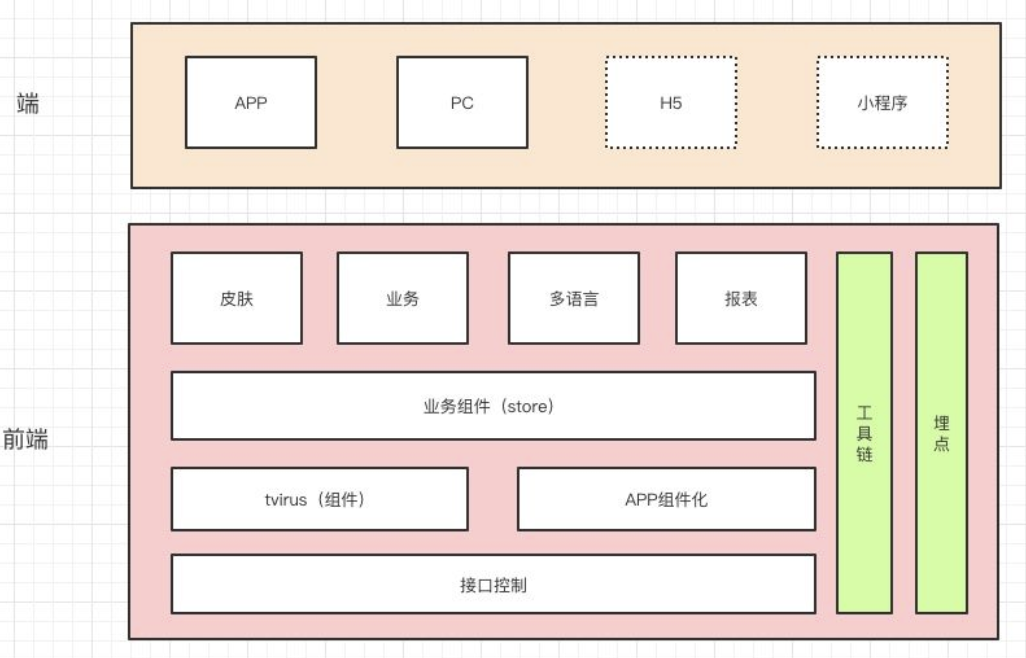
前端
前端使用react + react router 实现SPA单页应用。
选用react的原因是组件化支持较为良好,并且我们也没有ie相关的历史包袱(业务系统使用chrome访问)。
组件
关于UI组件,我们有一套根据业务建立的一套组件库T-virus
业务组件都封装在页面内,代码结构如下:
数据请求都封装在组件内部,方便组件复用,通过Ajax请求方法,添加精确到分钟的毫秒数来使用304缓存,提升http请求速度。
路由
按照上面图片的结构,自定义了一个webpack plugin 生成页面路由配置。
Plugin:
1 | class RouterPlugin { |
Bundle:
1 | import React from 'react'; |
生成后的router.json
1 | import Bundle from "Components/bundle"; |
利用react动态import()方法, 触发webpack的code spliting 实现路由的懒加载。
redux
关于数据流管理工具,我们的使用是相对克制的。
- redux增加组件的复杂度
- 我们的业务主要是数据渲染类,不重操作。
所以决定在页面层面的筛选条件 时间维度 使用react-redux,来减少数据层层透传的痛苦。各业务组件内部使用父级state。